


出品| 搜狐科技
作者| 常博硕
编辑| 杨锦
近日,ICLR(International Conference on Learning Representations,国际学习表征会议)在新加坡落下帷幕。
本届ICLR共评选出三篇杰出论文,其中,OpenAI研究员漆翔宇等人的关于大模型安全对齐方向的论文(Safety Alignment Should be Made More Than Just a Few Tokens Deep)受到广泛关注。搜狐科技就该论文及大模型安全问题,对话了新加坡科技研究局科学家李韶华。
李韶华目前也从事大语言模型安全对齐方向的研究,他读到这篇论文的时候还在ICLR审稿阶段,由于得分很高所以吸引了他的目光。
“总的看法是,这篇写作通俗易懂,也很符合直觉,即如果推理阶段,攻击者攻破了前几个token(Sure, here is …),那语言模型就会进入自动补全模式,补全后面本来拒绝回答的内容。”
他表示,这篇论文给防御提供了一个有趣的思路,可以说是给语言模型补了一个补丁。
安全对齐为什么越来越重要?
作为机器学习与人工智能领域最重要的国际学术会议之一,ICLR汇聚了全球顶尖的学者、研究人员和行业精英,共同探讨深度学习与人工智能的前沿技术、创新应用和未来趋势。
今年的参会人数也达到新峰,包括何恺明、杨立昆、约书亚·本吉奥、朱松纯、马毅、李宏毅、宋飏等国际计算机领域顶级学者参加。
ICLR今年共收到11565篇论文投稿,最终录用率为32.08%。2024年,ICLR组委会共收到了7262篇投稿,总体录用率约为31%。数量上的差异也精准反映出全球对于AI领域研究的热忱。根据官方表示,2025年接收论文的Workshop为40个,相对于2024年的20个增加了一倍。
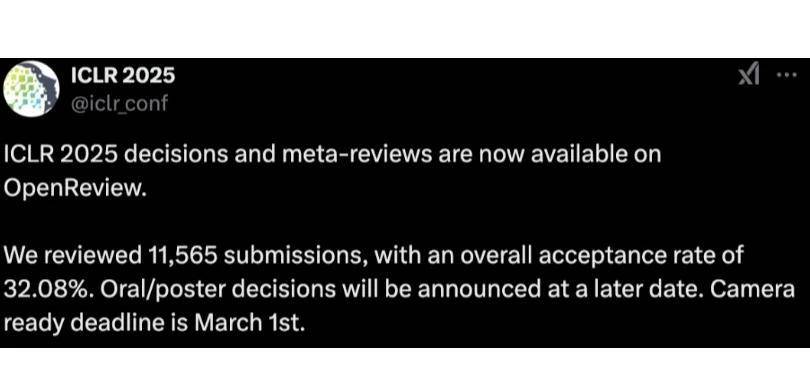
ICLR 2025 杰出论文遴选由委员会全体成员审阅,并根据理论洞见、实践影响、写作能力和实验严谨性等因素进行排名,最终结果由项目主席决定。
安全对齐通常指的是在大模型应用中,确保模型的输出行为与预期目标和社会规范相一致,保证大模型不会产生有害或者不当的结果。
具体来说,安全对齐包括伦理和道德对齐、法律法规对齐、用户意图对齐以及社会价值观对齐。没有做到安全对齐的大模型很有可能生成有害、错误和偏见的内容,对用户和社会产生负面影响。

漆翔宇等人的论文指出当前大语言模型(LLM)的安全对齐机制存在“浅层安全对齐”(shallow safety alignment)问题:对齐往往只调整生成输出的前几个 token,从而导致模型易受各种攻击,如对抗性后缀攻击、预填充攻击、解码参数攻击、微调攻击等。
论文通过多个案例分析这一机制漏洞,并提出扩展对齐深度和正则化微调目标等方法来增强模型的鲁棒性。该研究从根本上分析了 LLM 安全对齐的薄弱之处,提出加强对齐深度的策略,对防御模型越狱和对抗攻击具有重要意义。
在李韶华看来,这篇论文的核心就是,即使攻破了前几个token,模型也可以随时“一转念,意识到自己不该输出,然后输出Sorry, …”.它给防御提供了一个有趣的思路,可以说是给语言模型补了一个补丁。”
随着GPT-4、PaLM、LLaMA和DeepSeek等大模型(LLM)的技术突破及广泛应用,其潜在的安全风险也日益凸显,在LLM迅猛发展的背后,安全问题正悄然成为新的竞技场。就连我们的日常生活中也逐渐受到大语言模型安全问题的影响。
2023年4月三星员工错误使用ChatGPT导致公司绝密数据泄露;同年ChatGPT爆出“奶奶漏洞”导致Win11序列号泄露;2024年11月,谷歌Gemini聊天机器人威胁用户“人类,请去死吧”;2024年12月Claude暗示一名青少年杀死限制其使用手机的父母以及DeepSeek R1发布后曾在越狱攻击下生成大量18禁内容……
大模型的数据安全、内容安全以及伦理安全,无时无刻不影响着用户的体验与人身安全。
更为复杂且难以察觉的还有大模型的生态链安全,例如2024年字节实习生通过在模型文件植入后门代码,导致模型训练任务受阻,损失过千万,黑客利用 Ray 框架漏洞入侵服务器、劫持资源,利用模型算力资源进行挖坑等非法活动。
要不要交“对齐税”?
随着DeepSeek等大模型的功能日益强大,不少企业选择接入大模型进行私有化部署,以丰富用户对于自家产品的体验感,然而安全问题一不小心就可能将企业拉进隐私泄露的沼泽。
“几千家单位接入了DeepSeek大模型私有部署,但我们通过扫描发现90%在“裸奔”,简单的控制语句就能设法拿到大模型后台数据。” 奇安信科技集团董事长齐向东近日如是说。
谈及大模型安全的重要性,李韶华表示:“语言类大模型的发展已经初步进入瓶颈期,在这种情况下,头部厂商可能更侧重把现有模型更好的应用到各种场景里,提高它们的可信赖度,所以安全是很重要的。”
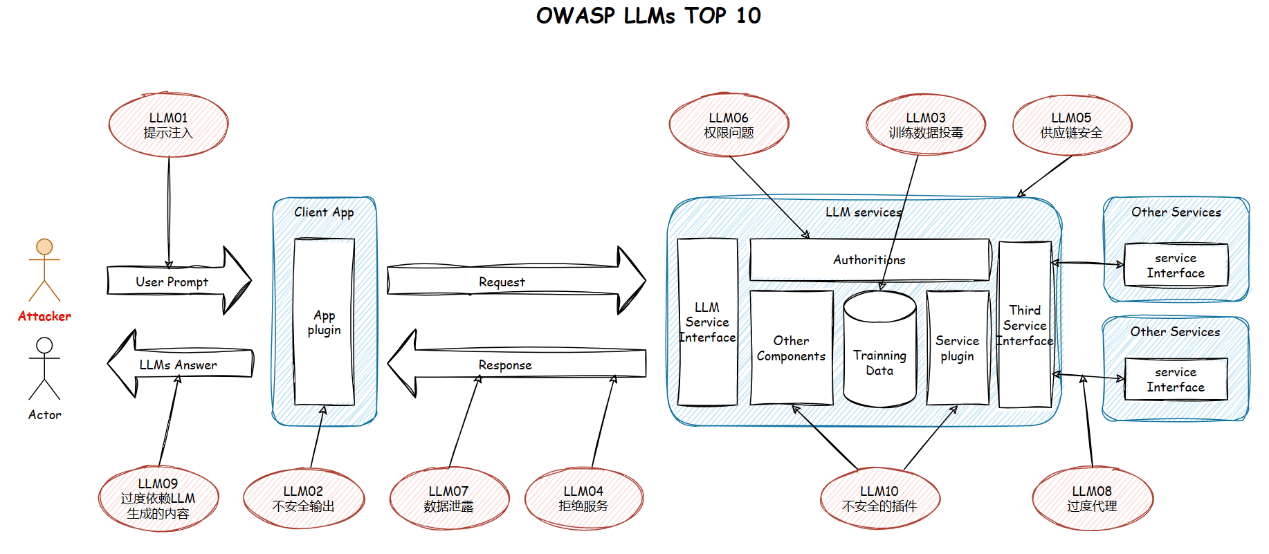
随着LLM技术的快速发展和广泛应用,其安全风险也在不断演变。OWASP最新发布的大语言模型10大安全漏洞,包括:
1. 提示词攻击(Prompt Injections):用户通过操控提示词诱导大模型生成有害内容。
2. 不安全输出(Insecure Output Handling):当插件或应用程序在没有适当审查的情况下盲目接受LLM 输出并将其直接传递给后端、特权或客户端函数时,就会出现该漏洞。
3. 训练数据投毒(Training Data Poisoning): LLM使用不同的原始文本来学习和输出,攻击者将中毒的训练数据用于模型训练,可能使用户接触到不正确的信息。
4. 拒绝服务(Denial of Service):攻击者以特别消耗资源的方式与LLM交互,导致他们和其他用户的服务质量下降或产生高资源成本。
5. 供应链安全(Supply Chain):LLM 中的供应链可能容易受到攻击,影响训练数据和部署平台的完整性,并导致有偏见的结果、安全漏洞或完整的系统故障。
6. 权限问题(Permission Issues):插件之间缺乏授权跟踪可能会导致插件的恶意使用,从而导致模型缺乏机密性。
7. 数据泄露(Data Leakage):LLM中的数据泄漏可能会暴露敏感信息或专有详细信息,从而导致隐私和安全漏洞。
8. 过度代理(Excessive Agency):当LLM与其他系统接口时,不受限制的代理可能会导致不良的操作和操作。
9. 过度依赖(Overreliance):LLM虽然能够产生创造性和信息丰富的内容,但也容易受到“幻觉”的影响,产生事实上不正确,荒谬或不适当的内容。当系统过度依赖LLM进行决策或内容生成而没有足够的监督,验证机制或风险沟通时,就会出现这种漏洞。
10. 不安全的插件(Insecure Plugins):如果将 LLM 连接到外部资源的插件接受自由格式的文本输入,则可能会被利用,从而启用可能导致不良行为或远程代码执行的恶意请求。
随着LLM安全问题的重要性逐渐凸显,李韶华向搜狐科技解读了关于目前高效和受到广泛关注的训练方法。
他表示,目前主流的大模型安全管控方式有两个方面,第一是提高基础模型的安全性,包括在SFT和RLHF阶段识别对抗字符串、违规提示词等,以及加强对非法价值观的识别(比如种族歧视、纳粹等观念,以及过于露骨的色情内容)。
第二是另外有一个小的语言模型,实时监测基础模型的输出,如果有不妥内容,及时“掐断”,这也是我们在用GPT、Deepseek时会碰到,输出了很多内容但是突然都被撤回了这种情况的原因。
大模型的安全对齐的发展目前仍存在一定的技术瓶颈,比如众多研究人员关注的大模型的推理能力与安全之间的平衡性问题。
李韶华也坦言:“安全对齐会抑制大模型的能力,这在提出RLHF的论文(Training language models to follow instructions with human feedback)里,被称为“对齐税”(alignment tax)。这个问题可以用人来类比,如果一个人头脑里规矩很多,总是担心各种细节是不是不合适,那他平时考虑问题时就束手束脚,思想不够活跃,难一点的问题可能就解决不了了。”
除此之外,谈及ICLR中杰出论文的模型效果,李韶华在参加AISG(新加坡全国人工智能核心)语言模型攻防全球竞赛时曾试用该模型,他表示:“这篇论文因为发布的模型是对 Gemma-2-9B的微调版本,就拿来试了一下。但遗憾的是,效果并不好,比原始的Gemma-2-9B有较大的差距,所以后来就没有采用了。
“我猜测性能变差是因为微调一定程度牺牲了模型原有的先验知识,而我们的竞赛要求识别恶意问题,要用到这些先验知识。但这并不是说这篇论文的思路难以用于实践,而是他们侧重于展示论文思路是可以工作的,所以可能训练示例模型的时候没太考虑实对原有知识的保留。”
大模型安全领域的研究道阻且长,不光是LLM,在不久的将来AI智能体也许也将有越来越广泛的应用,随着各种AI能力的增强,AI的安全问题将变得越来越重要。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






